
Page 109 - Computer_Science_F5
P. 109
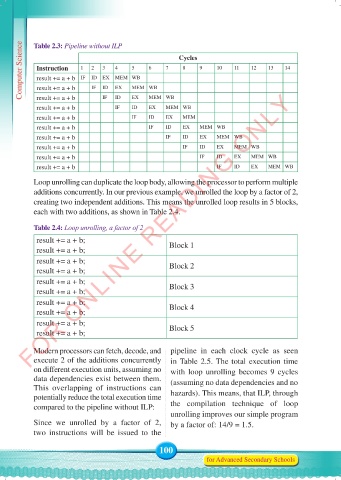
Computer Science Table 2.3: Pipeline without ILP 5 MEM WB 7 Cycles 9 10 11 12 13 14
Instruction
6
8
4
1
2
3
result += a + b
MEM WB
EX
ID
IF
result += a + b
ID
EX
IF
FOR ONLINE READING ONLY
result += a + b
result += a + b IF ID EX MEM WB
ID
IF
EX
MEM WB
result += a + b IF ID EX MEM
result += a + b IF ID EX MEM WB
result += a + b IF ID EX MEM WB
result += a + b IF ID EX MEM WB
result += a + b IF ID EX MEM WB
result += a + b IF ID EX MEM WB
Loop unrolling can duplicate the loop body, allowing the processor to perform multiple
additions concurrently. In our previous example, we unrolled the loop by a factor of 2,
creating two independent additions. This means the unrolled loop results in 5 blocks,
each with two additions, as shown in Table 2.4.
Table 2.4: Loop unrolling, a factor of 2
result += a + b; Block 1
result += a + b;
result += a + b;
result += a + b; Block 2
result += a + b; Block 3
result += a + b;
result += a + b; Block 4
result += a + b;
result += a + b;
result += a + b; Block 5
Modern processors can fetch, decode, and pipeline in each clock cycle as seen
execute 2 of the additions concurrently in Table 2.5. The total execution time
on different execution units, assuming no with loop unrolling becomes 9 cycles
data dependencies exist between them. (assuming no data dependencies and no
This overlapping of instructions can
potentially reduce the total execution time hazards). This means, that ILP, through
compared to the pipeline without ILP: the compilation technique of loop
unrolling improves our simple program
Since we unrolled by a factor of 2, by a factor of: 14/9 = 1.5.
two instructions will be issued to the
100
for Advanced Secondary Schools
Computer Science Form 5.indd 100 23/07/2024 12:33